
Die tägliche Information über aktuelle Cybersecurity-Nachrichten stellt eine Herausforderung dar. Während verschiedenste Nachrichtenquellen in RSS-Readern, Slack-Channels und Social-Media-Feeds verteilt sind, besteht ein großes Risiko relevante Meldungen zu übersehen. Ein Experiment mit KI-gestützter Nachrichtenaggregation sollte dieses Problem adressieren – und brachte dabei wichtige Erkenntnisse über die Grenzen von LLM-basierten Suchen mit sich.
Das Initial-Konzept: Intelligente Nachrichtenpriorisierung mit KI
Die zentrale Idee war bestechend einfach: Nicht jeder Data Breach und nicht jede Sicherheitslücke ist im eigenen Kontext relevant. Täglich muss die enorme Menge an Cybersecurity-Informationen gefiltert und priorisiert werden. Ein automatisierter Bot könnte genau diese Aufgabe übernehmen – aktuelle Nachrichten evaluieren und täglich über einen Kanal wie Slack pushen.
Die technische Umsetzung sollte auf einem bestehenden Toolset basieren: Perplexity für die KI-Verarbeitung, Cloudflare Workers für die Orchestrierung und Slack als Zustellungskanal. Der Workflow war konzeptionell klar: täglich eine Perplexity Query mit definiertem Prompt ausführen, Nachrichten priorisieren und per Slack-Webhook in den entsprechenden Channel pushen.
Erster Versuch: KI-basierte Nachrichtensuche und das Problem der Halluzinationen
Der erste Ansatz nutzte Cloudflare Workers für einen relativ aufwändigen Prompt an die Perplexity API:
Bitte die aktuellen, relevanten Cybersecurity-Nachrichten der letzten beiden Arbeitstage (heute und letzter Arbeitstag) für Unternehmen in der DACH-Region (Deutschland, Österreich, Schweiz) bereitstellen. Fokus liegt auf bedeutenden Datenpannen, Hacks und Sicherheitslücken mit hoher Relevanz für die Region. Bitte bevorzuge Nachrichtenquellen aus dem DACH-Raum, aber internationale Quellen sind ebenfalls akzeptabel, wenn sie für die Region relevant sind. Bitte bevorzuge Nachrichtenquellen, die eher Nachrichtenartikel als Beiträge von Herstellern sind - außer es handelt sich um Sicherheitslücken, welche Hersteller selber publizieren. Nutze Quellen ähnlich wie: {‘, ‘.join(NEWS_SOURCES)}. Antworte ausschließlich mit einem JSON-Array von Objekten, ohne zusätzlichen Text oder Markdown. Jedes Objekt enthält folgende Felder.
- headline (String)
- excerpt (String)
- source_url (String)
Beschränke die Antwort auf {max_items} Einträge.
Der Prompt forderte ein strukturiertes JSON-Array mit Überschrift, Zusammenfassung und Quelle. Die Ergebnisse wurden ebenfalls über Cloudflare Workers an einen Slack Webhook weitergeleitet und über Cron täglich um 9 Uhr ausgelöst.
Nach aufwändigerer Umsetzung als erwartet funktionierte der Prozess zunächst – täglich erschienen 5 Nachrichten inklusive Überschrift, Zusammenfassung und Link in Slack.

Der erste Klick auf einen Link offenbarte das Problem: 404-Fehlerseite. Beim Auftreten des gleichen Fehlers bei einer weiteren Quelle wurde klar – die Links funktionierten systematisch nicht. Eine Recherche über Suchmaschinen konnte keine echten Artikel finden, die den beschriebenen Nachrichten entsprachen.
Die Diagnose war überraschend: Perplexity selbst bestätigte, dass diese Nachrichten komplett halluziniert waren. Das Tool generierte nicht nur erfundene Artikel, sondern auch gefälschte Links – die allerdings perfekt dem URL-Schema der jeweiligen Nachrichtenwebseiten entsprachen. Dies ist ein bekanntes Problem bei Large Language Models: Sie können überzeugend falsche Informationen präsentieren, besonders wenn sie Daten generieren sollen, die sie nicht direkt in ihrem Training-Datensatz haben.
Wichtiges Learning: LLM-basierte Suchen sind für tagesaktuelle Nachrichten ungeeignet, wenn sie nicht mit den jeweiligen Datenquellen verbunden werden. Die Modelle halluzinieren bei Informationen, die außerhalb ihres Training-Datensatzes oder bei echtzeitabhängigen Anfragen liegen.
Zweiter Versuch: RSS Feeds mit KI-basierter Priorisierung
Eine Neuausrichtung des Ansatzes war erforderlich. Statt die KI zur Nachrichtensuche einzusetzen, sollte sie nur die Priorisierung und Zusammenfassung übernehmen. Die Datenquelle für aktuelle Nachrichten: klassische RSS Feeds von bekannten Cybersecurity-Nachrichtenquellen.
Der neue Workflow wurde mit n8n realisiert:
- RSS-Aggregation: n8n ruft mehrere definierte RSS Feeds ab und erstellt ein konsolidiertes JSON-Objekt
- Filtering: Alle Einträge älter als 24 Stunden werden entfernt, um doppelte Nachrichten bei täglicher Ausführung zu vermeiden
- KI-Priorisierung: Perplexity erhält die gefilterten Artikel und wird angewiesen, diese zu qualifizieren – also auf bestimmte Themen zu fokussieren und die wichtigsten Artikel zusammenzufassen
- Slack-Zustellung: Die priorisierten Nachrichten werden als strukturiertes Array (Überschrift, Zusammenfassung, Link) an einen Slack Webhook übermittelt
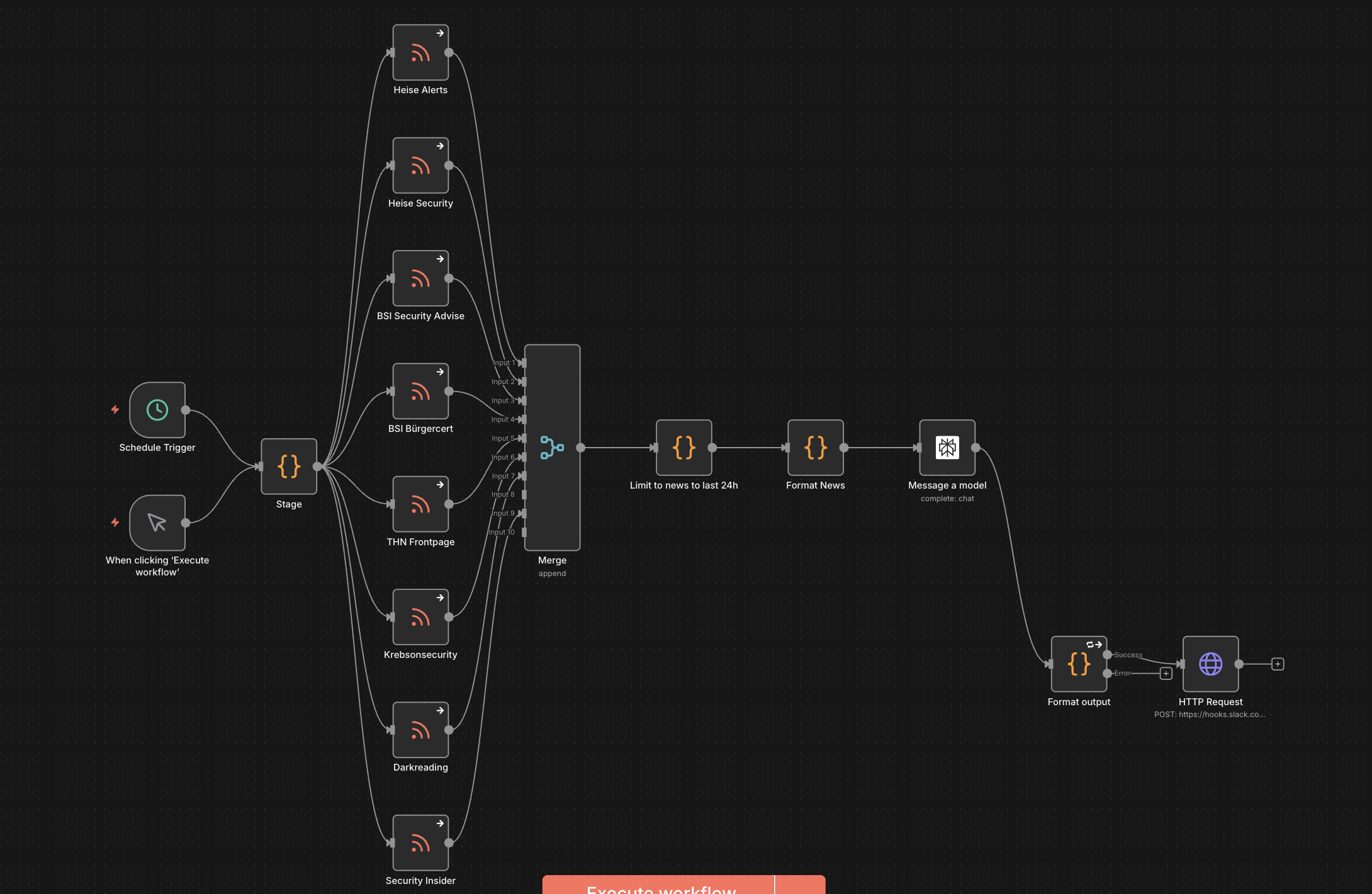
Das Ergebnis war deutlich besser. Keine halluzinierten Nachrichten mehr, keine 404-Fehler. Die Priorisierung der Inhalte durch die KI erwies sich als zuverlässig und relevant. Der Proof-of-Concept läuft bereits mehrere Wochen im Security Meetup Slack und erhielt durchweg positives Feedback. Die priorisierten Nachrichten stehen konsistent an erster Stelle der Liste.
Trade-off: Der Ansatz ist auf vordefinierte Nachrichtenquellen mit RSS-Feeds beschränkt. Eine dynamische Einbindung neuer Quellen ist in der aktuellen Implementierung nicht vorgesehen – für das Ziel der gezielten Nachrichtenpriorisierung aber absolut ausreichend.
Technische Details: Warum der zweite Ansatz funktioniert
Der Schlüssel zum Erfolg liegt darin, der KI keine Generierungsaufgabe zu geben, sondern eine Evaluierungsaufgabe. LLMs sind sehr stark bei:
- Klassifizierung und Priorisierung: Das Bewerten vorliegender Inhalte
- Zusammenfassung: Das Extrahieren von Kernaussagen aus existierenden Texten
- Strukturierung: Das Organisieren von Informationen in vordefinierte Formate
Sie sind schwach bei:
- Echtzeitsuche: Informationen abrufen, die außerhalb des Training-Datensatzes liegen
- Aktuelle Fakten: Tagesaktuelle Events korrekt wiedergeben
- Quellenverifizierung: Überprüfen, ob generierte Quellenangaben tatsächlich existieren
Diese Grenzen zu verstehen ist essentiell für sinnvolle KI-Automation.
Fazit und Weiteres Learning
Der erste Versuch mit Cloudflare Workers und direkter KI-Suche war zeitaufwändig und führte letztlich zu halluzinierten Ergebnissen – aber auch zu einem wichtigen Learning. Dass KI bei Echtzeitdaten an ihre Grenzen stößt, ist nicht neu, aber im praktischen Einsatz deutlich spürbarer als in der Theorie.
Der zweite Ansatz mit n8n und RSS-Feeds als Datenquelle bewies, dass ein sauberer Workflow und ein klar definiertes Problem (Priorisierung statt Suche) deutlich bessere Ergebnisse liefert. Darüber hinaus sind die ersten Gehversuche mit n8n überzeugend – das Tool bietet große Potenziale für zukünftige Automationen im Bereich Cybersecurity Research und darüber hinaus.